手機(jī)顯示云服務(wù)器 從新手機(jī)遷移數(shù)據(jù)是否麻煩?無(wú)需擔(dān)心,OPPO云服務(wù)為您提供全方位數(shù)據(jù)處理與存儲(chǔ)

在當(dāng)今數(shù)字化時(shí)代,手機(jī)已成為我們生活中不可或缺的一部分,其中存儲(chǔ)的聯(lián)系人、照片、文檔和應(yīng)用數(shù)據(jù)更是珍貴。當(dāng)用戶(hù)更換新手機(jī)時(shí),最令人頭疼的問(wèn)題莫過(guò)于數(shù)據(jù)的遷移與備份。幸運(yùn)的是,隨著云服務(wù)技術(shù)的飛速發(fā)展,這一過(guò)程已變得前所未有的簡(jiǎn)單與高效。特別是對(duì)于OPPO用戶(hù)而言,其內(nèi)置的云服務(wù)器功能,讓數(shù)據(jù)遷移從一項(xiàng)繁瑣任務(wù)轉(zhuǎn)變?yōu)檩p松便捷的體驗(yàn)。
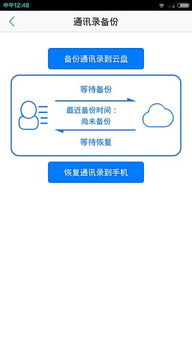
我們來(lái)理解什么是手機(jī)顯示器云服務(wù)器。它并非指手機(jī)的物理屏幕,而是指通過(guò)云端服務(wù)器來(lái)顯示、管理和同步手機(jī)數(shù)據(jù)的一種服務(wù)。用戶(hù)可以將手機(jī)中的數(shù)據(jù)自動(dòng)備份到云端,然后在任何設(shè)備上訪問(wèn)這些數(shù)據(jù)。這種服務(wù)極大地?cái)U(kuò)展了手機(jī)的存儲(chǔ)能力,并確保了數(shù)據(jù)的安全與可移植性。
對(duì)于從新手機(jī)遷移數(shù)據(jù)是否麻煩的問(wèn)題,答案是否定的——如果您充分利用了云服務(wù)。以O(shè)PPO云服務(wù)為例,其設(shè)計(jì)初衷就是為了簡(jiǎn)化這一過(guò)程。用戶(hù)只需在舊手機(jī)上登錄OPPO賬戶(hù)并開(kāi)啟云備份功能,系統(tǒng)便會(huì)自動(dòng)將聯(lián)系人、短信、通話記錄、照片、視頻、文檔乃至部分應(yīng)用數(shù)據(jù)上傳至云端。當(dāng)您拿到新手機(jī)時(shí),只需使用同一賬戶(hù)登錄,選擇從云端恢復(fù)數(shù)據(jù),系統(tǒng)就會(huì)自動(dòng)將備份的數(shù)據(jù)下載并配置到新設(shè)備上。整個(gè)過(guò)程幾乎無(wú)需手動(dòng)干預(yù),大大節(jié)省了時(shí)間和精力。
您是否擁有OPPO云服務(wù)?即便您之前未曾使用,現(xiàn)在開(kāi)始也毫不費(fèi)力。OPPO云服務(wù)通常預(yù)裝在ColorOS系統(tǒng)中,用戶(hù)只需在設(shè)置中輕松找到并激活。它提供一定量的免費(fèi)存儲(chǔ)空間,足以滿足大多數(shù)用戶(hù)的基本需求。如果您需要更多空間,還可以通過(guò)訂閱計(jì)劃進(jìn)行擴(kuò)容。更重要的是,OPPO云服務(wù)采用了高級(jí)加密技術(shù),確保您的數(shù)據(jù)在傳輸和存儲(chǔ)過(guò)程中安全無(wú)虞,免除了隱私泄露的后顧之憂。
在數(shù)據(jù)處理和存儲(chǔ)服務(wù)方面,OPPO云服務(wù)不僅限于備份與恢復(fù)。它還支持多設(shè)備同步,意味著您在一臺(tái)設(shè)備上更新的數(shù)據(jù)會(huì)實(shí)時(shí)同步到所有登錄同一賬戶(hù)的設(shè)備上。服務(wù)通常包括照片的智能分類(lèi)、文件的在線編輯與管理等功能,讓數(shù)據(jù)管理變得更加智能高效。對(duì)于企業(yè)用戶(hù)或重度用戶(hù),這種服務(wù)還能作為額外的數(shù)據(jù)冗余方案,防止因設(shè)備丟失或損壞導(dǎo)致的數(shù)據(jù)永久丟失。
從新手機(jī)遷移數(shù)據(jù)已不再是一件麻煩事。借助OPPO云服務(wù)這類(lèi)先進(jìn)的云服務(wù)器解決方案,用戶(hù)可以無(wú)縫過(guò)渡到新設(shè)備,享受連續(xù)、安全的數(shù)據(jù)體驗(yàn)。無(wú)論您是科技愛(ài)好者還是普通用戶(hù),擁抱云服務(wù)都將讓您的數(shù)字生活更加輕松自在。所以,下次換機(jī)時(shí),請(qǐng)放心依賴(lài)云端的力量,讓數(shù)據(jù)遷移成為一次簡(jiǎn)單的點(diǎn)擊之旅。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.www4238com.cn/product/61.html
更新時(shí)間:2026-05-28 01:32:16